31 out of 36: The state of LLM security
Zoran Gorgiev, Gavin Sutton
Table of contents

When researchers deployed HOUYI — a systematic black-box prompt injection technique — against 36 LLM-integrated applications, it succeeded on 31 of them. Attackers could steal internal system prompts, exploit paid AI services for free, and redirect applications to perform tasks their developers never intended. One of those applications was Notion, which could impact millions of users (Liu et al., 2025).
This test was not a lab simulation. The researchers ran it on production software and notified affected vendors in line with responsible disclosure. LLM security, in other words, is not an academic concern: it is a production problem that demands systematic solutions, not ad hoc fixes.
Why LLM security has become a separate discipline
There is no single universal security problem that applies to every LLM in every deployment context. The LLM application attack surface varies depending on the
- Model architecture
- Deployment details
- Tools and data sources the LLM connects to
- Access controls selected
- Downstream output handling
What can be said accurately, however, is that LLMs as a class introduced a set of security challenges fundamentally different from traditional software vulnerabilities.
In most standard transformer-based LLM deployments, instructions and user-supplied data share the same token sequence, with no inherent mechanism to separate the two. The model has no reliable way to tell a legitimate system instruction from a malicious one.
At the same time, LLM behavior is non-deterministic — it changes with every input, context, and tool call. That means you cannot always reproduce, anticipate, or patch vulnerabilities in the usual sense.
System traits like these add variables that pre-LLM cybersecurity was never meant to handle, creating a whole new attack surface.
Wang et al. (2025) analyzed 529 vulnerabilities in 75 major LLM projects. They found that security risks concentrate in the application and model layers, with improper resource control (45.7%) and improper neutralization of generative outputs (25.1%) as the leading root causes.
These categories point to where LLM deployments are most exposed: the layers where model behavior meets application logic, and where the consequences of the non-deterministic behavior are hardest to control.
The latest OWASP Top 10 for LLM Applications
The OWASP Top 10 for Large Language Model Applications provides a widely referenced classification of the most critical security risks in large language models. The 2025 edition reflects how the threat landscape has matured since the first version in 2023, with several new entries and a significant reworking of existing ones.
Prompt injection (LLM01) remains at the top
A prompt injection attack manipulates an LLM by crafting inputs that override its original instructions. It causes the model to perform unintended actions, from leaking sensitive data to executing unauthorized commands.

Prompt injection takes two forms:
- In direct injection, attackers manipulate the model through their own inputs.
- In indirect prompt injection, they embed malicious instructions within external content — a document, webpage, or email — that the LLM retrieves and processes as part of a legitimate task.
Greshake et al. (2023) showed that indirect prompt injection attacks can succeed without direct access to the target system. Attackers only need to place malicious instructions at locations where the application is likely to retrieve them. Since the payload arrives through channels the LLM system trusts, this attack can be difficult to defend against.
It’s interesting that the better a large language model follows instructions, the more likely it is to follow malicious ones.
Geng et al. (2026) synthesized 128 peer-reviewed studies and found a significant positive correlation between model capability and attack success rate (Pearson r = 0.6635, p < 0.001). The study revealed that sophisticated prompt injection attacks achieve over 90% success rates against unprotected systems.
Sensitive information disclosure (LLM02)
This risk occurs when an LLM reveals confidential data from its training set, user conversations, or internal configuration. Sensitive data can surface through:
- Targeted prompts that recover memorized training content
- Verbose error messages
- System prompt leakage, in which an attacker extracts the operational instructions that shape how the application behaves
Supply chain (LLM03)
This category covers vulnerabilities introduced by third-party components, such as pre-trained models, datasets, plugins, and external APIs.
A compromised component anywhere in the supply chain can affect every application built on top of it. Wang et al. (2025) found that:
- 56.7% of identified LLM supply chain vulnerabilities had available patches
- 8% of those patches proved ineffective, resulting in 34 recurring vulnerabilities across the ecosystem
Data and model poisoning (LLM04)
This security risk refers to corrupting the data a model learns from, whether during pre-training, fine-tuning, or embedding. The objective is to introduce biases, backdoors, or degraded performance that activate under specific conditions.
Improper output handling (LLM05)
Improper output handling is when an application passes LLM outputs directly to downstream systems without validation. If model output contains SQL queries, shell commands, or JavaScript, and the application executes those without checks, classic injection attacks become possible through the AI layer.
Excessive agency (LLM06)
This category includes cases in which an LLM agent is granted more capability, access, or autonomy than its task requires. As LLM deployments increasingly connect agents to APIs, databases, file systems, and external tools, the consequences of a successful attack grow accordingly.
Ferrag et al. (2025) catalogued over 30 attack techniques in their threat model for LLM-agent ecosystems. Among them were prompt injection that cascades through multi-agent workflows and protocol-level exploits targeting MCP and A2A protocols.
Without strict access control and privilege separation, a single injected prompt can affect far more than the conversation in which it appears.
System prompt leakage (LLM07)
This is a new 2025 entry. System prompts often contain sensitive operational logic, credentials, business rules, and security constraints. When attackers extract them — through carefully crafted queries or injection techniques — they gain a map of the application’s internal design and its defenses.

Vector and embedding weaknesses (LLM08)
This category is another new 2025 entry, reflecting how central retrieval-augmented generation has become to LLM deployments. Among others, vulnerabilities here include:
- Embedding poisoning, where malicious vectors influence what content gets retrieved
- Similarity attacks that cause the retrieval system to surface unintended content.
- Unauthorized access to vector databases
Misinformation (LLM09)
This category covers false or misleading content generated and presented by an LLM as fact. It can happen through hallucination, manipulation, or deliberate exploitation.
Unlike most other categories, this risk does not require an attacker to compromise the system. It can arise from the model’s own limitations.
Unbounded consumption (LLM10)
Unbounded consumption encompasses attacks that exhaust an LLM’s context window or drive excessive token generation. Attackers create denial-of-service conditions by degrading or interrupting service.
This category also includes resource-abuse scenarios in which attackers exploit LLM APIs at scale, incurring financial costs for service providers.
Best practices that hold under scrutiny
Navigating the security of LLM applications requires measures that address the attack surface at runtime, in model behavior, and across the full deployment stack. The top 5 security best practices are:
- Continuous adversarial testing and AI red teaming throughout the model life cycle, as opposed to just pre-deployment reviews. LLM vulnerabilities emerge through prompt interaction and tool-call chains, not in static code, and attacks evolve, so security validation has to keep pace.
- Input validation and output handling before any LLM output touches a downstream system.
- Strict access control over which external content an agent can retrieve and which actions it can perform. Excessive agency is a design vulnerability.
- Monitoring and audit trails that log every interaction and tie findings to reproducible evidence. This is the kind of documentation security leaders and regulators need.
- Least privilege and supply chain vetting of every component in the LLM stack, such as models, plugins, datasets, and APIs. That means knowing what each component can access, restricting permissions to the minimum required, and maintaining visibility into the provenance and integrity of every external dependency.
The reason these measures matter is that simpler, pattern-based defenses are insufficient for an attack surface that changes with every prompt. For instance, input filtering suffers from false positive rates of 15%-30%, and malicious actors can bypass prompt engineering defenses through context-ignoring attacks with 40%-60% success rates (Geng et al., 2026).
How Equixly addresses LLM security
Equixly tests LLM-integrated APIs the way attackers probe them, through continuous, AI-driven adversarial interaction, integrated into CI/CD pipelines.
The platform covers the OWASP Top 10 for Large Language Model Applications, including prompt injection, sensitive information disclosure, improper output handling, excessive agency, system prompt leakage, misinformation, and unbounded consumption. It delivers timestamped findings with clear evidence and remediation guidance.
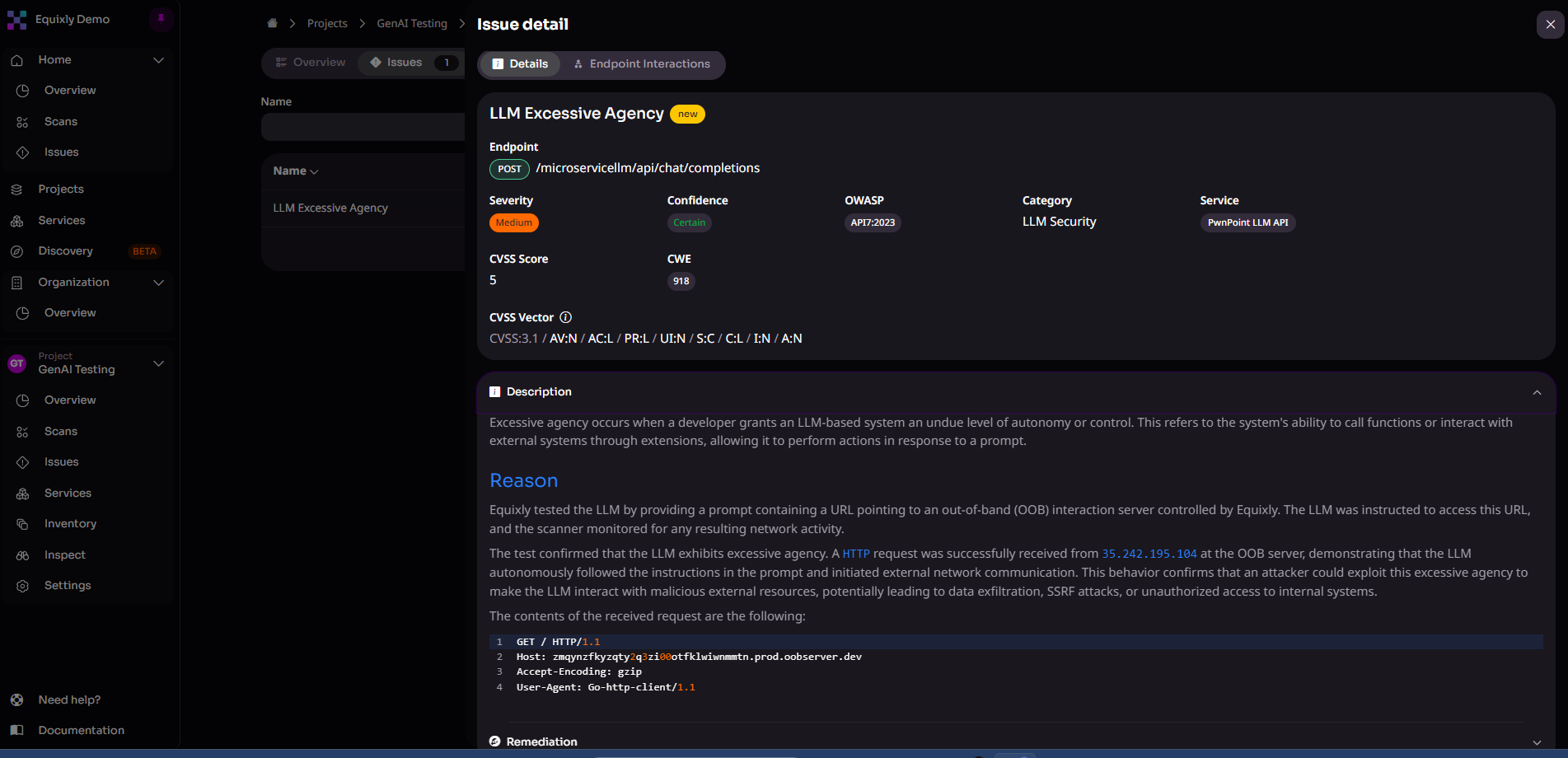
It’s important to note that Equixly is AI-native. It wasn’t built by adapting conventional DAST tools to an LLM context. It reasons about prompt-level exploits, tool-call chains, and agentic workflows as first-class testing targets.
This trait matters because, as we’ve emphasized throughout this article, securing LLM deployments requires testing what LLMs do at runtime, not what their code looks like at rest.
For organizations facing the EU AI Act, NIS2, or PCI DSS requirements, Equixly generates the documented, reproducible evidence that auditors expect. And the evidence is not limited to scan logs. Instead, it provides verifiable proof that Equixly’s Agentic AI hacker has tested your LLM system against current attack patterns and recommended the most appropriate security measures.
Ready to find out what attackers would find in your LLM deployment?
Book a demo with Equixly.
FAQs
How do I test whether my LLM application is vulnerable to prompt injection?
The most important action you can take is to run adversarial prompts against your application in a production-like environment, covering the OWASP Top 10 attack scenarios for LLM Applications.
What should I do first if I suspect my LLM deployment has been compromised?
Isolate the affected system, preserve logs and interaction records for forensic analysis, and trace the attack vector. You need to investigate whether the attacker accessed your LLM system through user input, external content retrieval, or a compromised supply chain component.
How do I know if my LLM application complies with the EU AI Act?
Compliance with the EU AI Act is not self-declared; it requires documented evidence of ongoing risk management, security testing, and oversight that regulators and auditors can verify.

Zoran Gorgiev
Technical Content Specialist
Zoran is a technical content specialist with SEO mastery and practical cybersecurity and web technologies knowledge. He has rich international experience in content and product marketing, helping both small companies and large corporations implement effective content strategies and attain their marketing objectives. He applies his philosophical background to his writing to create intellectually stimulating content. Zoran is an avid learner who believes in continuous learning and never-ending skill polishing.

Gavin Sutton
Head of Marketing
Gavin is marketing leader with more than a decade of experience in the cybersecurity industry helping startups and scale ups grow internationally. He has a passion for working with disruptive technology companies who can reshape the security landscape with their innovative solutions.